coding & analysis
R and RStudio are essential components of most (if not all) of my workflows. From geospatial projects and data analysis, to data visualizations and producing documents and reports, R is an incredibly powerful tool. Here are some examples of ways I have used R to conduct my own analysis, provide research support, assist colleagues, and for my own pet projects. You can also check out some source code for the projects in knitted R Markdown files.
climate change effects on Virginia reservoirs
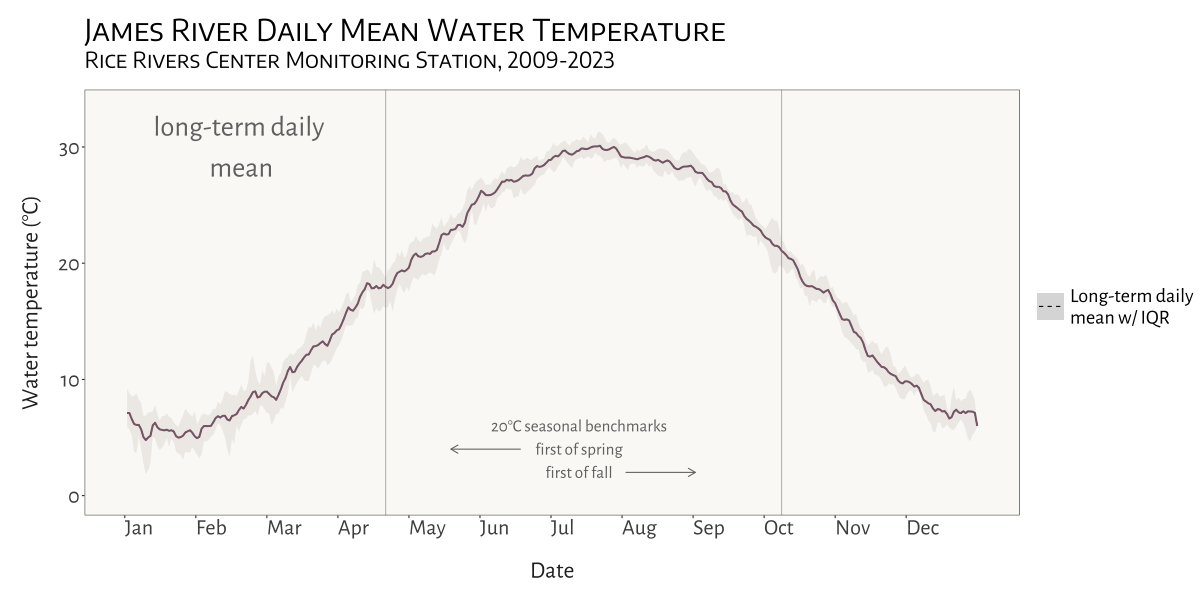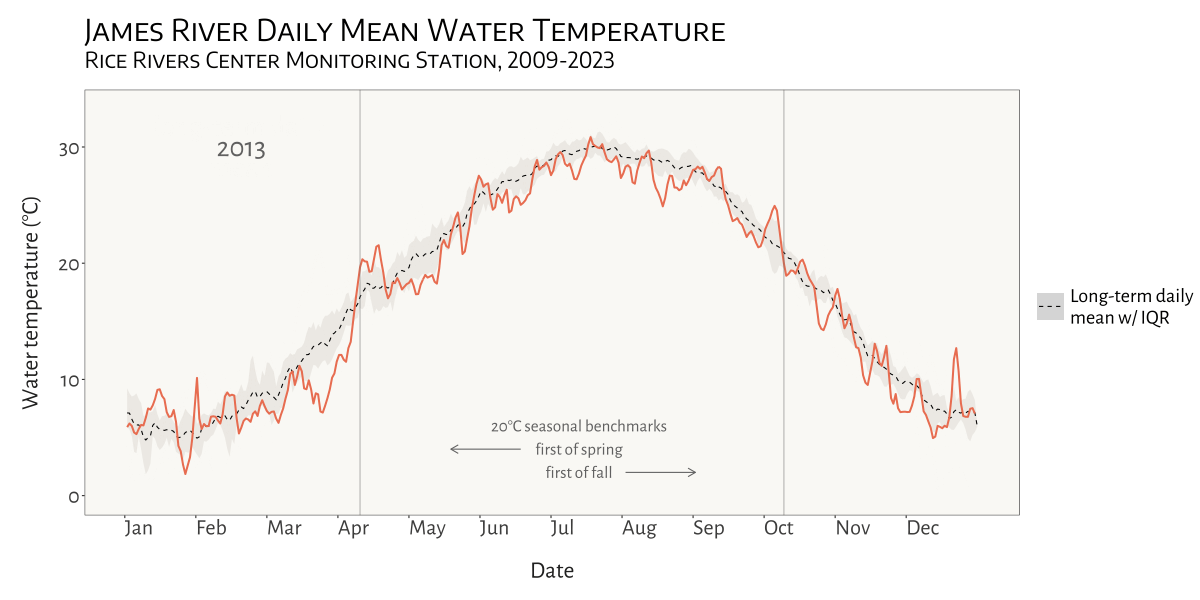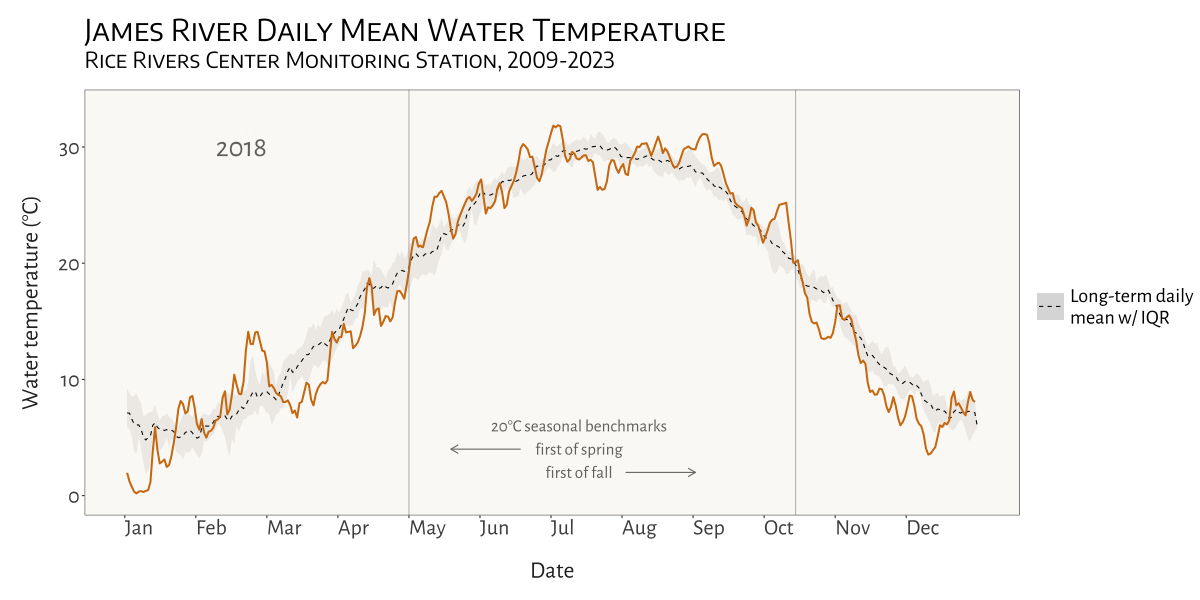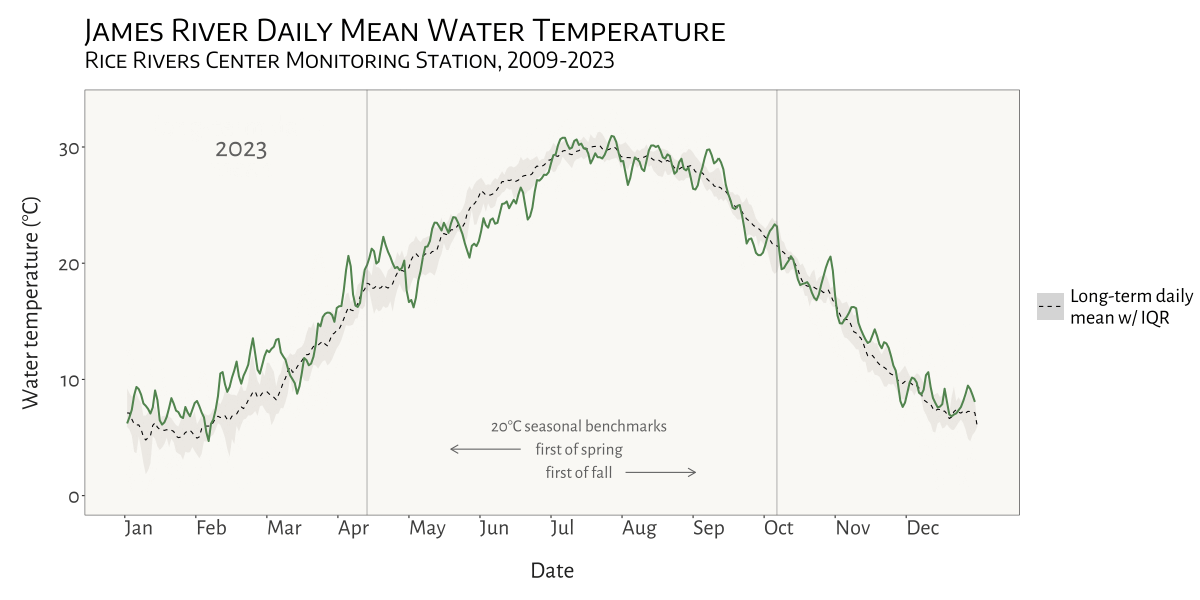
My most recent project for the Bukaveckas Lab at VCU involved analyzing the effects of climate change on Virginia reservoirs. Between February and July of 2024 I contributed to a forthcoming peer-reviewed publication that examines the effects of climate change on reservoirs throughout Virginia. This involved carrying out median-based linear modeling (MBLM) to assess long-term trends in temperature and dissolved oxygen at 41 lake stations across the state. MBLM was selected for its robustness to outliers, which ensured more reliable results in the presence of irregular data points, occurring either as a result of extreme weather conditions or instrument error. The analysis was based on a large data set from Virginia Department of Environmental Quality comprising ~19,00 profiles from over 500 stations across more than 100 reservoirs in the state. The stations selected for the study were chosen based on their having at least 100 profiles available for analysis. For each station, month-by-month trends from May to October were calculated, along with intra-annual trends focusing on the period from April to August each year.
I really enjoyed this project, not only because it gave me a chance
to learn about and apply a new statistical method in the context of
valuable climate-focused research, but because it presented me with some
opportunities for data visualization and applying my GIS and spatial
analysis chops. Exploratory analysis involved, among other things,
testing various environmental factors, such as latitude, longitude, to
uncover potential spatial gradients and temporal patterns that might
explain variability in the data. I had a rewarding - if rather
challenging - experience trying to create a plot, using our data, based
on a figure from another publication. This involved some pretty advanced
ggplot2 concepts to achieve the desired formatting and
layout. Plus, I got to make a cool map (!) for publication that shows
the locations of the trend analysis sites and the watersheds they are
located in. This gave me a chance to try to develop a compelling color
scheme and layout that was be both visually appealing and
informative.
All in all, this project is built on quite a few Markdown files. Below are a couple of examples.
- source code for deriving DO trends and producing corresponding box-whisker plots
- source code for deriving Apr to Aug site trends + generating plot
visualizing water temperature over time
Another fun and challenging project I was able to do for the Bukaveckas Lab involved combining 15 years of water quality monitoring data to generate daily mean summary statistics for select variables, as well as produce an animated plot depicting seasonal patterns and inter-annual variation in water temperature at VCU’s Rice River Center monitoring station.
This required quite a bit of wrangling and problem solving to get from A to B. I made extensive use of nested list structures to organize and manage the data, which allowed me to systematically separate and categorize data by year and tab across and within Excel workbook files. This was critical given the inconsistency in the data schema and variable naming conventions over the 15 years that data were collected.
I was already familiar with R’s ggplot2 before beginning
this project, but the need for a dynamic plot gave me the chance to
explore the gganimate package - something I look forward to
doing more of in the future!
bird diversity in grassland vs forest ecosystems
class-level landscape metrics as predictors of avian species richness
For this analysis, completed as the final project for landscape ecology (ENVS 591) during the fall of 2023 at VCU, I was interested in exploring the extent to which class-level landscape metrics differ in their ability to explain variation in avian species richness (total # of different species) in grassland ecosystems versus forest ecosystems.
The whole project was carried out using R in
RStudio, and was a great opportunity to conduct a spatial analysis
outside of a point-and-click GIS environment. Not using ArcGIS Pro meant
not enjoying the convenience of ‘on-the-fly projection’, which required
me to be especially attentive to coordinate reference systems and
projections as I prepared spatial data from different sources for
analysis. I also became familiar with a number of great spatial R
packages and APIs, including mapview, terra,
sf, raster, FedData, and
landscapemetrics.
This project gave me a chance to work with data sets from the National Ecology Observatory Network (NEON), a comprehensive ecological monitoring program that collects standardized, high-quality data from diverse ecosystems across the United States.
Check out the maps below - which I made in R using the
mapview package - to see the NEON sites used in my
analysis.
My analysis used three years of data (2019-2021) from three separate
study areas in each of the two landscape types. Study areas comprised
10-20 distinct study plots, with each ‘plot-year’ combination
representing a unique sampling event (n=228). For each plot-year, I
derived the total number of bird species observed. I pulled in National
Land Cover Data using FedData and generated buffers around
each plot-year at 200m, 500m, 1000m, and 2000m in order to assess the
influence of landscape metrics at different spatial scales.
Before calculating landscape metrics I first reclassified the NLCD
data using a reclassification matrix to produce new raster datasets with
simplified land cover categories (forest, agricultural, and urban). I
then used the landscapemetrics package to calculate 5
class-level metrics for each buffer size:
Five landscape metrics across four buffer sizes produced a total of
20 variables to be considered as potential predictors of species
richness in each ecosystem type. Given time constraints, I took a bit of
a shortcut to select variables for modelling. I utilized a tiered
hierarchical approach by applying the corSelect() function
from the fuzzySim package (v. 4.10.5). Minimally correlated
variables were first selected at each spatial extent and those selected
variables were then further evaluated together to make a final
selection. The approach was pragmatic, but I would like to eventually
return to this analysis and tailor variable selection by better
integrating domain-specific ecological knowledge.
With variables selected, I applied a generalized linear mixed model approach to incorporate study area as a random effect. This produced a ‘singular fit’, however, indicating that the model was overfitted – that is, the random effects structure was too complex to be supported by the data. Instead, I utilized multiple regression to fit models for every possible combination of predictor variable, then compared models using AIC to select the top performers and identify the most important predictors.
tl;dr version
- In mid-Atlantic forests, only elevation and % forest cover were found to be significant predictors of avian species richness.
- In grasslands, both PLAND at 1000m and AI at 1000m were found to be significant predictors.
- A significantly higher amount of variation in avian species richness was explained by grassland model (42.6%) than forest models (<12%).
Here’s a PDF version of a presentation that gives a more detailed look at some of the results.
gun data preprocessing automation
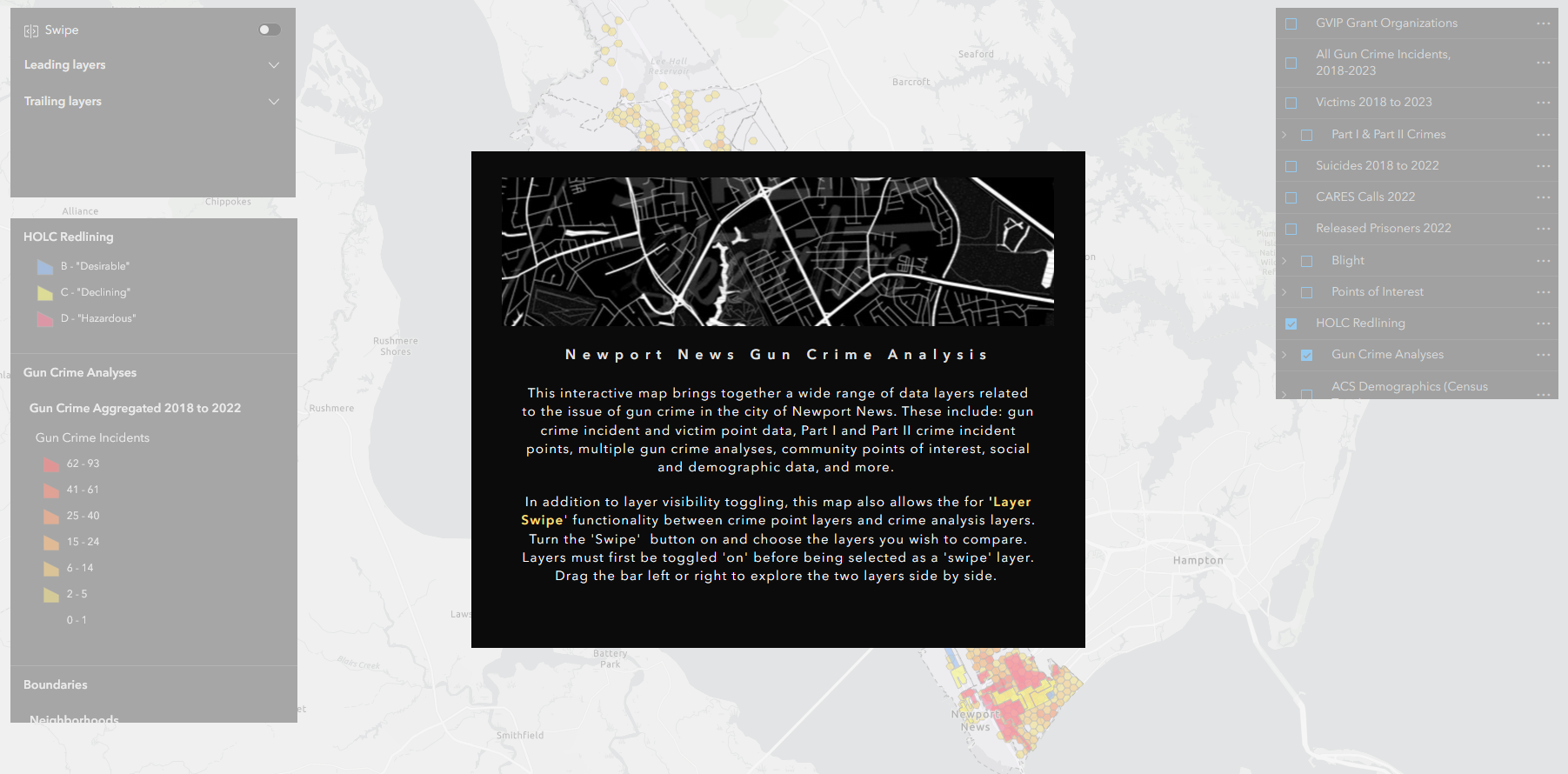
The urban gun crime work that I did during my time as a member of the City of Newport News GIS team gave me the chance to carry out some interesting spatial analyses and work on developing several apps with the Esri tool kit, including Experience Builder, Dashboards, and web maps (none of which are public-facing, unfortunately). But in order to get to that point, the data generated from the police department’s record management system query first needed substantial massaging and preparation.
To accommodate the need for re-running analyses and updating the dashboard annually or semi-annually with new data, I developed a script to automate the otherwise laborious task of preprocessing the raw RMS query outputs. I wrote the script in a heavily annotated R Markdown file, so that future users can easily interact with it using RStudio’s ‘visual’ mode and execute the code with little to no knowledge of R required. The user needs only to define two variables: a new folder name and the path of the Excel workbook file containing the raw data. The script takes care of the rest. The end result is two CSV files ready to be brought into ArcGIS Pro and geocoded.
modelling estuarine algal blooms
I’ve been fortunate to be able to provide water quality research assistance to the Bukaveckas Lab at Virginia Commonwealth University, in the form of program scripting, data analysis, and data visualization, since December of 2023.
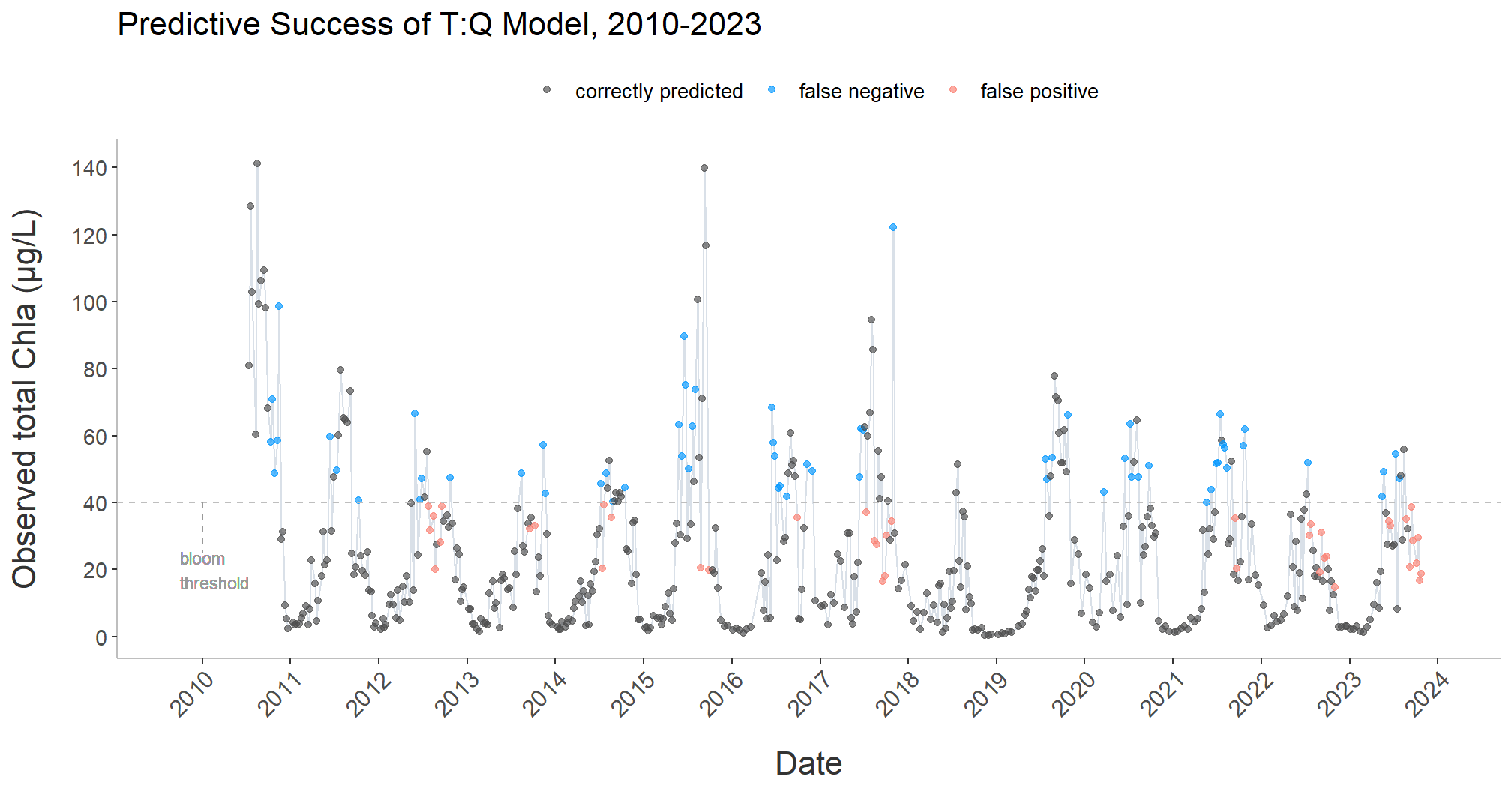
Among other projects, I developed a script to facilitate the longitudinal analysis and modeling of chlorophyll a (CHLa) levels in the James River using multiple linear and nonlinear approaches.
The knitted HTML output contains tables with summary statistics for the all years in the data set; regression statistics for all years combined, as well as individual years, by model; model plots with best fit line; model-specific time series plots; and time series plots for CHLa and dissolved organic nitrogen.
The script is designed to dynamically adapt to changes in the dataset, accommodating new data from subsequent years without requiring manual updates to its structure or content.
More detailed program documenation is available on my Github page.
intro to osmdata
This was less a coding project and more a way to help folks in my office use some basic coding to programmatically access the OpenStreetMap database.
Newport News, VA has an amazing Geohub site, but - for obvious reasons - the city does not maintain spatial data layers on every feature that exists in the city. After a colleague shared in a meeting that she had to quickly put together a suitability analysis using features that she pulled in from multiple sources around the web - e.g., shopping, grocery stores, cinemas, bowling alleys, and sundry other sites for leisure activities - it occurred to me that the GIS team could benefit from being able to leverage the OpenStreetMap API in this sort of situation, should it arise again in the future.
I created a tutorial, adapting from this
excellent
and more comphrensive vignette on the CRAN website, for using
R’s osmdata package. It is written with the goal that
someone who had never used R or RStudio before would nevertheless be
able to access the API, pull in the data they are looking for, and
export it as a JSON that they can pull into the ArcGIS Pro environment
for use in mapping and analysis.